Czy naprawdę potrzebujesz dostępu SSH do serwera za każdym razem, gdy chcesz wdrożyć nową wersję aplikacji? W nowoczesnym podejściu DevOps coraz częściej odpowiedź brzmi: nie.
Docker pozwala tworzyć powtarzalne środowiska uruchomieniowe, które działają identycznie na komputerze programisty, serwerze testowym i produkcji. Dzięki temu zespoły mogą ograniczyć ręczne działania, zmniejszyć liczbę błędów środowiskowych i automatyzować wdrożenia.
Największą wartością Dockera nie jest samo uruchamianie kontenerów. Kluczowe znaczenie ma przewidywalność środowiska oraz możliwość traktowania infrastruktury w podobny sposób jak kodu aplikacji.

Dlaczego aplikacja działa lokalnie, ale nie działa na serwerze
Jednym z najczęstszych problemów podczas wdrażania aplikacji są różnice pomiędzy środowiskiem lokalnym a produkcyjnym.
Przyczyną mogą być odmienne wersje bibliotek, brakujące pakiety, różne ustawienia systemowe lub błędy konfiguracji. Nawet niewielka rozbieżność może prowadzić do nieoczekiwanych problemów po wdrożeniu.
Docker eliminuje ten problem poprzez zamknięcie aplikacji wraz z jej zależnościami w jednym kontenerze. Dzięki temu środowisko pozostaje identyczne niezależnie od miejsca uruchomienia.
Właśnie dlatego w świecie programistów tak często pojawia się zdanie „u mnie działa”, które zwykle oznacza różnice między środowiskami.
Najczęstsze mity dotyczące Dockera
Wokół Dockera narosło wiele nieporozumień.
| Mit | Rzeczywistość |
|---|---|
| Docker jest maszyną wirtualną | Kontenery działają znacznie lżej niż VM |
| Docker służy wyłącznie produkcji | Jest powszechnie używany także podczas developmentu |
| Docker rozwiązuje wszystkie problemy | Nadal potrzebne są testy, monitoring i dobre praktyki |
Pierwszy mit dotyczy porównania do maszyn wirtualnych. Kontenery nie emulują całego systemu operacyjnego i wykorzystują zasoby znacznie efektywniej.
Drugim błędem jest przekonanie, że Docker jest potrzebny wyłącznie na produkcji. W rzeczywistości wiele zespołów korzysta z niego przede wszystkim podczas codziennego developmentu.
Docker znacząco upraszcza zarządzanie środowiskami, ale nie zastępuje odpowiedniego procesu wytwarzania oprogramowania.
Czym naprawdę jest konteneryzacja
Konteneryzacja polega na uruchamianiu aplikacji w odizolowanych środowiskach zawierających wszystkie niezbędne zależności.
Podstawowym elementem jest obraz kontenera. Można go traktować jako kompletny szablon środowiska aplikacji.
Na podstawie obrazu uruchamiany jest kontener, czyli działająca instancja programu.
Największą zaletą tego podejścia jest przewidywalność. Ten sam obraz może zostać uruchomiony na komputerze programisty, w środowisku testowym oraz na produkcji bez konieczności dodatkowej konfiguracji.
Dzięki temu zespoły ograniczają problemy związane z różnicami środowiskowymi i przyspieszają proces wdrażania.
Dockerfile jako przepis na środowisko aplikacji
Dockerfile opisuje sposób budowania obrazu kontenera.
Zawiera instrukcje określające bazowy system, instalowane pakiety, kopiowane pliki oraz proces uruchamiania aplikacji.
Najważniejszą korzyścią jest pełna powtarzalność procesu budowania środowiska.
- Programista definiuje środowisko w Dockerfile.
- System buduje obraz na podstawie tych instrukcji.
- Ten sam obraz może zostać uruchomiony w dowolnym środowisku.
Każda zmiana jest wersjonowana razem z kodem źródłowym, co ułatwia kontrolę oraz odtwarzanie wcześniejszych konfiguracji.
Największą zaletą Dockera nie jest samo uruchamianie kontenerów, lecz możliwość traktowania infrastruktury w sposób powtarzalny, wersjonowany i przewidywalny.
Praca z wieloma usługami dzięki Docker Compose
Nowoczesne aplikacje często wymagają działania kilku usług jednocześnie.
Typowy projekt może składać się z aplikacji, bazy danych, systemu cache oraz dodatkowych komponentów wspierających.
Docker Compose pozwala definiować całe środowisko w jednym pliku konfiguracyjnym. Dzięki temu wszystkie usługi mogą zostać uruchomione jednym poleceniem.
Szczególnie doceniają to nowe osoby dołączające do zespołu. Zamiast ręcznie instalować wszystkie komponenty, mogą uruchomić kompletne środowisko projektu w ciągu kilku minut.
To znacząco skraca proces onboardingu i zmniejsza liczbę problemów konfiguracyjnych.
Dlaczego nowoczesne zespoły odchodzą od SSH
Coraz więcej organizacji ogranicza bezpośrednie logowanie do serwerów produkcyjnych.
Popularność zdobywa podejście określane jako Immutable Infrastructure. Zamiast ręcznie modyfikować działające środowisko, przygotowuje się nową wersję obrazu i wdraża ją automatycznie.
Takie rozwiązanie oferuje kilka istotnych korzyści:
- większe bezpieczeństwo
- pełną powtarzalność wdrożeń
- łatwiejszy audyt zmian
- mniej błędów wynikających z ręcznej konfiguracji
Dzięki temu infrastruktura staje się bardziej przewidywalna i łatwiejsza w utrzymaniu.
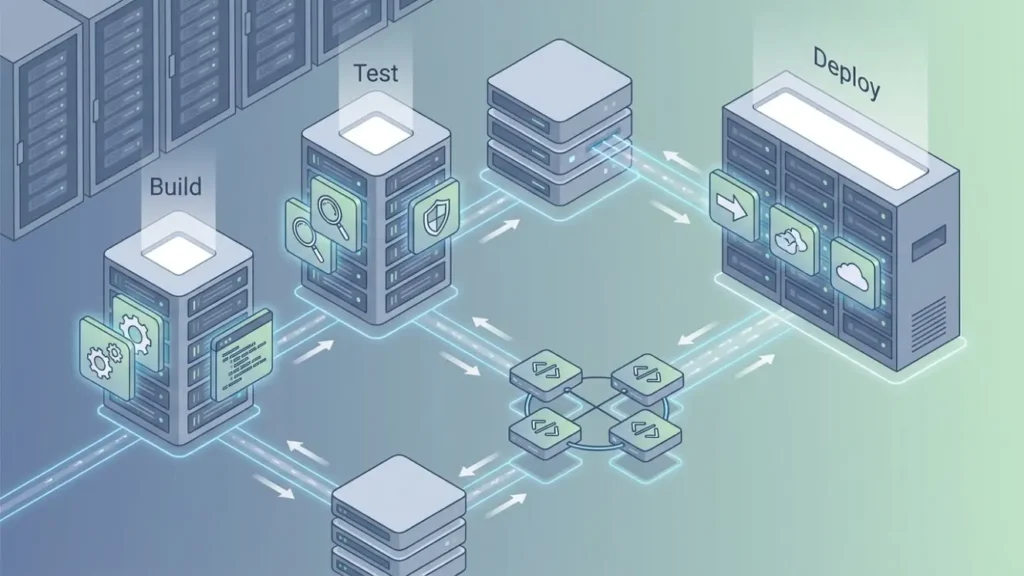
Docker i CI/CD – naturalne połączenie
Docker i CI/CD tworzą dziś jeden z najczęściej spotykanych fundamentów nowoczesnych procesów DevOps.
Pipeline może automatycznie budować obrazy kontenerów, uruchamiać testy oraz wdrażać gotowe wersje aplikacji.
To oznacza, że każda zmiana przechodzi przez identyczny proces niezależnie od środowiska.
W wielu zespołach Docker początkowo wykorzystywany jest wyłącznie podczas developmentu. Z czasem te same obrazy trafiają do testów automatycznych i środowisk produkcyjnych.
Takie podejście ogranicza liczbę błędów oraz zwiększa przewidywalność całego procesu dostarczania oprogramowania.
W jakich projektach Docker sprawdza się najlepiej
Docker znajduje zastosowanie w większości nowoczesnych projektów, jednak szczególnie dobrze sprawdza się w aplikacjach webowych, systemach SaaS oraz architekturach mikroserwisowych.
Jest również bardzo popularny w startupach, gdzie szybkie wdrażanie nowych funkcji i łatwe skalowanie środowiska mają kluczowe znaczenie.
Nie oznacza to jednak, że każdy projekt wymaga Dockera od pierwszego dnia. Technologia ta przynosi największe korzyści wtedy, gdy rozwiązuje realne problemy związane z konfiguracją, wdrożeniami lub współpracą zespołu.
Docker znacząco upraszcza proces dostarczania aplikacji, jednak największe korzyści pojawiają się wtedy, gdy kontenery zostaną połączone z automatyzacją budowania, testowania i wdrażania. Jeśli chcesz lepiej zrozumieć cały proces, warto również przeczytać artykuł „Continuous Integration/Deployment – CI/CD pipeline od zera”.